scoringutils 2.1.2
- fixed an issue that could arise with small rounding errors in
quantile-based forecasts. This happened when there were quantile_levels
like 0.5, and 0.5 + 1e-16 present at the same time.
scoringutils now warns the user of the issue and
automatically rounds all quantile levels to 10 digits.
- updated a few example plots to comply with an updated ggplot2
requirement to name labels in
labs() explicitly.
scoringutils 2.1.1
- The package now depends on R version at least 4.1.0 as a result of
downstream dependencies.
- Added tolerance for numeric errors when checking that probabilities
sum to one in ordinal forecasts (#997)
- Made computation of p-values optional in pairwise comparisons by
allowing
test_type = NULL in
compare_forecasts(). When test_type = NULL,
p-values will be NA (#978).
- Added a dependency on a scoringRules version >= 1.1.3 which is
required for ordinal forecasts and the
rps_probs() function
(#1006,#1011).
- A bug was fixed in PIT histograms from continuous values (#1010).
The bug caused all PIT histograms to use the discrete version, even with
continuous data. In the calculations, values were also rounded
inappropriately.
scoringutils 2.1.0
Minor spelling / mathematical updates to Scoring rule vignette.
(#969)
Package updates
- A bug was fixed where
crps_sample() could fail in edge
cases.
- All
as_forecast_<type>() functions now have S3
methods for converting from another forecast type to the respective
forecast type.
- Implemented a new forecast class,
forecast_ordinal with
appropriate metrics. Ordinal forecasts are a form of categorical
forecasts. The main difference between ordinal and nominal forecasts is
that the outcome is ordered, rather than unordered.
- Refactored the way that columns get internally renamed in
as_forecast_<type>() functions (#980)
- The package now correctly specifies a dependency on
data.table >= 1.16.0.
scoringutils 2.0.0
This update represents a major rewrite of the package and introduces
breaking changes. If you want to keep using the older version, you can
download it using
remotes::install_github("epiforecasts/scoringutils@v1.2").
The update aims to make the package more modular and customisable and
overall cleaner and easier to work with. In particular, we aimed to make
the suggested workflows for evaluating forecasts more explicit and
easier to follow (see visualisation below). To do that, we clarified
input formats and made them consistent across all functions. We
refactord many functions to S3-methods and introduced
forecast objects with separate classes for different types
of forecasts. A new set of as_forecast_<type>()
functions was introduced to validate the data and convert inputs into a
forecast object (a data.table with a
forecast class and an additional class corresponding to the
forecast type (see below)). Another major update is the possibility for
users to pass in their own scoring functions into score().
We updated and improved all function documentation and added new
vignettes to guide users through the package. Internally, we refactored
the code, improved input checks, updated notifications (which now use
the cli package) and increased test coverage.
The most comprehensive documentation for the new package after the
rewrite is the revised
version of our original
scoringutils paper.
Package updates
score()
- The main function of the package is still the function
score(). However, we reworked the function and updated and
clarified its input requirements.
- The previous columns “true_value” and “prediction” were renamed.
score() now requires columns called “observed” and
“predicted” (some functions still assume the existence of a
model column as default but this is not a strict
requirement). The column quantile was renamed to
quantile_level and sample was renamed to
sample_id
score() is now a generic. It has S3 methods for the
classes forecast_point, forecast_binary,
forecast_quantile, forecast_sample, and
forecast_nominal, which correspond to the different
forecast types that can be scored with scoringutils.score() now calls na.omit() on the data,
instead of only removing rows with missing values in the columns
observed and predicted. This is because
NA values in other columns can also mess up e.g. grouping
of forecasts according to the unit of a single forecast.score() and many other functions now require a
validated forecast object. forecast objects
can be created using the functions as_forecast_point(),
as_forecast_binary(), as_forecast_quantile(),
and as_forecast_sample() (which replace the previous
check_forecast()). A forecast object is a data.table with
class forecast and an additional class corresponding to the
forecast type (e.g. forecast_quantile).
score() now returns objects of class scores
with a stored attribute metrics that holds the names of the
scoring rules that were used. Users can call get_metrics()
to access the names of those scoring rules.score() now returns one score per forecast, instead of
one score per sample or quantile. For binary and point forecasts, the
columns “observed” and “predicted” are now removed for consistency with
the other forecast types.- Users can now also use their own scoring rules (making use of the
metrics argument, which takes in a named list of
functions). Default scoring rules can be accessed using the function
get_metrics(), which is a a generic with S3 methods for
each forecast type. It returns a named list of scoring rules suitable
for the respective forecast object. For example, you could call
get_metrics(example_quantile). Column names of scores in
the output of score() correspond to the names of the
scoring rules (i.e. the names of the functions in the list of
metrics).
- Instead of supplying arguments to
score() to manipulate
individual scoring rules users should now manipulate the metric list
being supplied using purrr::partial() and
select_metric(). See ?score() for more
information.
- the CRPS is now reported as decomposition into dispersion,
overprediction and underprediction.
- functionality to calculate the Probability Integral Transform (PIT)
has been deprecated and replaced by functionality to calculate PIT
histograms, using the
get_pit_histogram() function; as part
of this change, nonrandomised PITs can now be calculated for count data,
and this is is done by default
Creating a forecast object
- The
as_forecast_<type>() functions create a
forecast object and validates it. They also allow users to
rename/specify required columns and specify the forecast unit in a
single step, taking over the functionality of
set_forecast_unit() in most cases. See
?as_forecast() for more information.
- Some
as_forecast_<type>() functions like
e.g. as_forecast_point() and
as_forecast_quantile() have S3 methods for converting from
another forecast type to the respective forecast type. For example,
as_forecast_quantile() has a method for converting from a
forecast_sample object to a forecast_quantile
object by estimating quantiles from the samples.
Updated workflows
An example workflow for scoring a forecast now looks like
this:
forecast_quantile <- as_forecast_quantile(
example_quantile,
observed = "observed",
predicted = "predicted",
model = "model",
quantile_level = "quantile_level",
forecast_unit = c("model", "location", "target_end_date", "forecast_date", "target_type")
)
scores <- score(forecast_quantile)
Overall, we updated the suggested workflows for how users should
work with the package. The following gives an overview (see the updated
paper for more details). 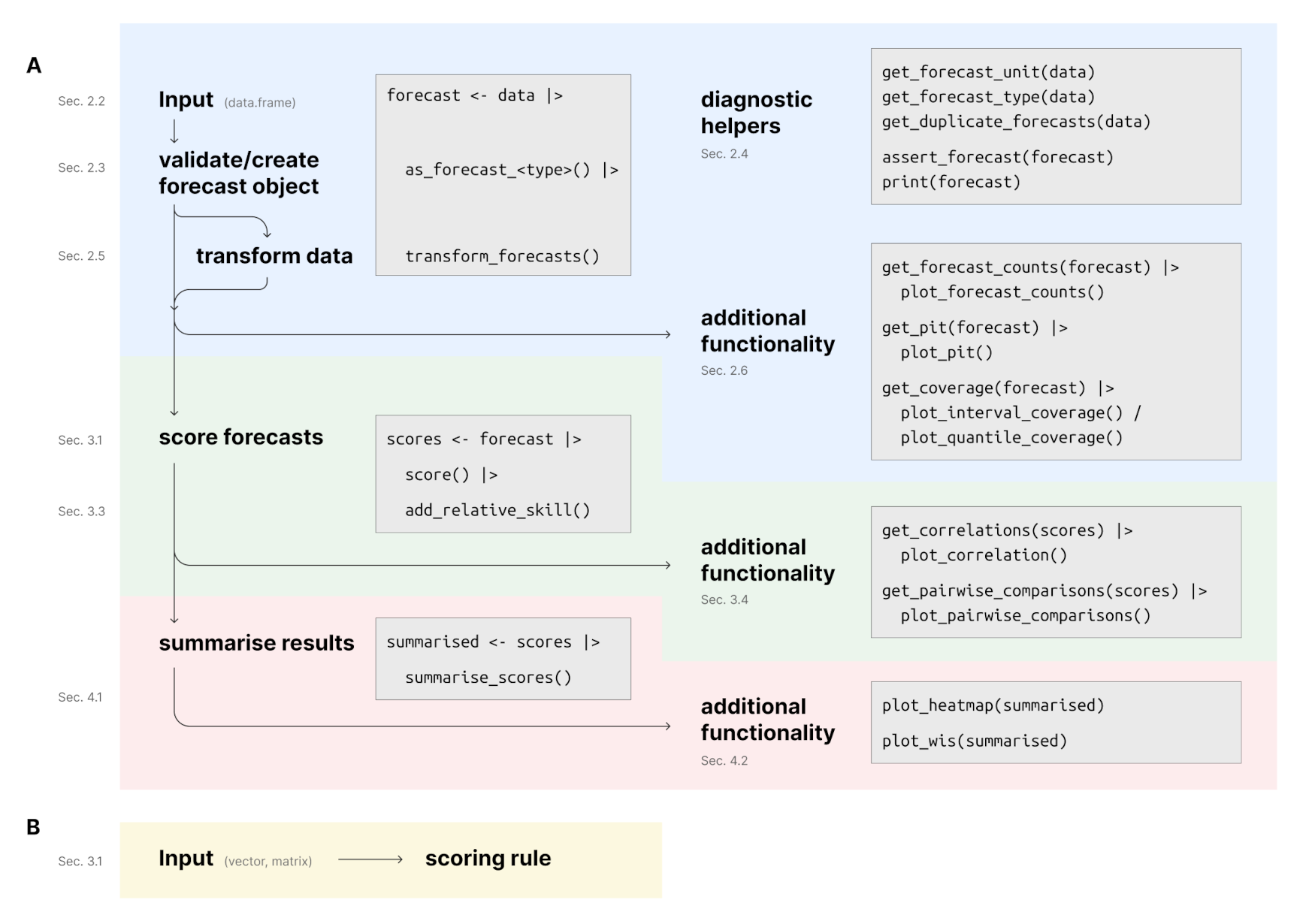
We standardised input formats both for score() as
well as for the scoring rules exported by scoreingutils.
The following plot gives a overview of the expected input formats for
the different forecast types in score(). 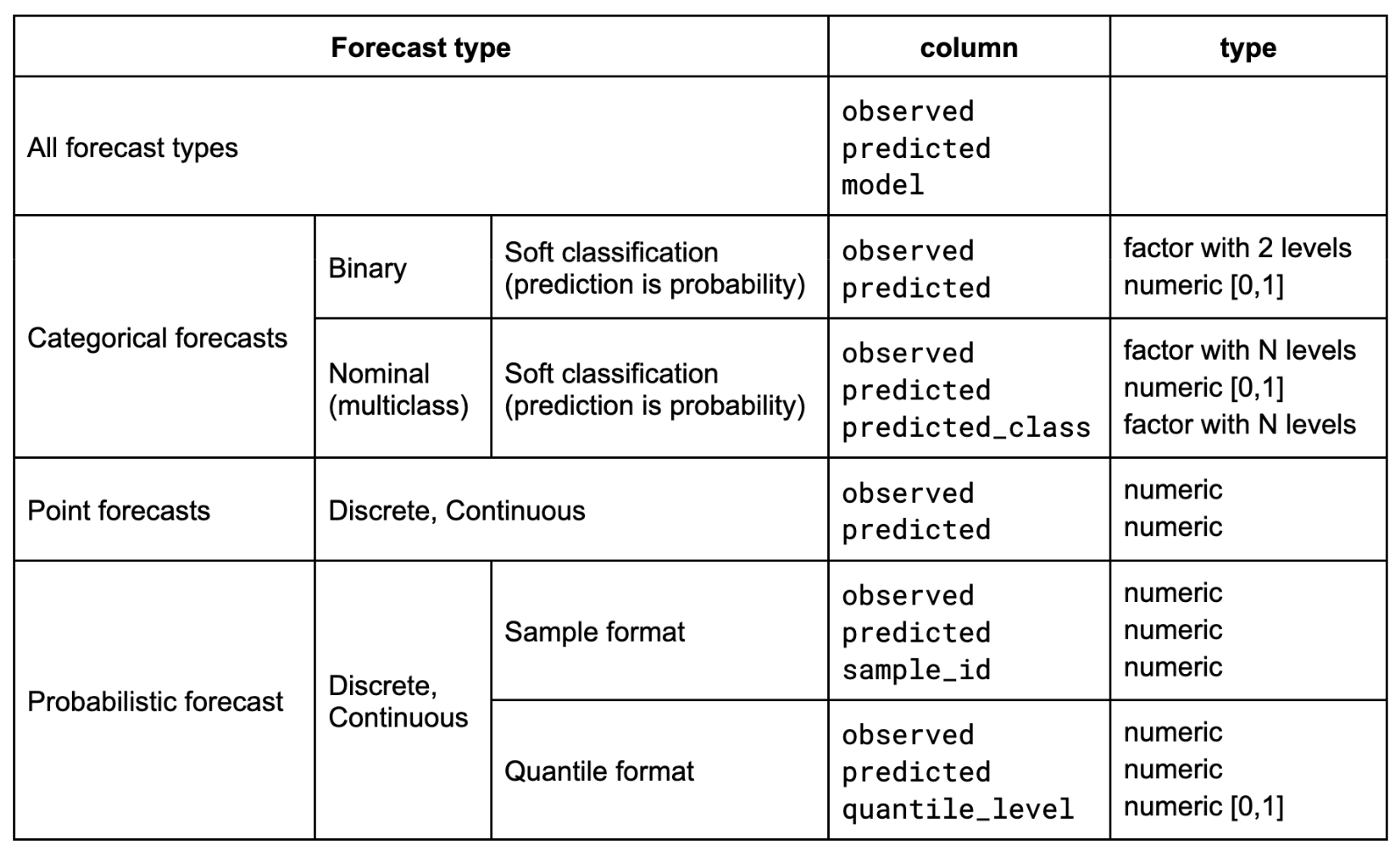
Support for the interval format was mostly dropped (see PR #525
by @nikosbosse and
reviewed by @seabbs).
The co-existence of the quantile and interval format let to a confusing
user experience with many duplicated functions providing the same
functionality. We decided to simplify the interface by focusing
exclusively on the quantile format.
- The function
bias_range() was removed (users should now
use bias_quantile() instead)
- The function
interval_score() was made an internal
function rather than being exported to users. We recommend using
wis() instead.
(Re-)Validating forecast
objects
- To create and validate a new
forecast object, users can
use as_forecast_<type>(). To revalidate an existing
forecast object users can call
assert_forecast() (which validates the input and returns
invisible(NULL). assert_forecast() is a
generic with methods for the different forecast types. Alternatively,
users can call `as_forecast_<type>() again to
re-validate a forecast object. Simply printing the object will also
provide some additional information.
- Users can test whether an object is of class
forecast_*() using the function is_forecast().
Users can also test for a specific forecast_* class using
the appropriate is_forecast.forecast_* method. For example,
to check whether an object is of class forecast_quantile,
you would use you would use
scoringutils:::is_forecast.forecast_quantile().
Pairwise comparisons
and relative skill
- The functionality for computing pairwise comparisons was now split
from
summarise_scores(). Instead of doing pairwise
comparisons as part of summarising scores, a new function,
add_relative_skill(), was introduced that takes summarised
scores as an input and adds columns with relative skill scores and
scaled relative skill scores.
- The function
pairwise_comparison() was renamed to
get_pairwise_comparisons(), in line with other
get_-functions. Analogously,
plot_pairwise_comparison() was renamed to
plot_pairwise_comparisons().
- Output columns for pairwise comparisons have been renamed to contain
the name of the metric used for comparing.
- Replaced warnings with errors in
get_pairwise_comparison to avoid returning
NULL
Computing coverage values
add_coverage() was replaced by a new function,
get_coverage(). This function comes with an updated
workflow where coverage values are computed directly based on the
original data and can then be visualised using
plot_interval_coverage() or
plot_quantile_coverage(). An example workflow would be
example_quantile |> as_forecast_quantile() |> get_coverage(by = "model") |> plot_interval_coverage().
Obtaining and plotting
forecast counts
- The function
avail_forecasts() was renamed to
get_forecast_counts(). This represents a change in the
naming convention where we aim to name functions that provide the user
with additional useful information about the data with a prefix “get_”.
Sees Issue #403 and #521 and PR #511 by @nikosbosse and reviewed by @seabbs for details.
- For clarity, the output column in
get_forecast_counts()
was renamed from “Number forecasts” to “count”.
get_forecast_counts() now also displays combinations
where there are 0 forecasts, instead of silently dropping corresponding
rows.plot_avail_forecasts() was renamed
plot_forecast_counts() in line with the change in the
function name. The x argument no longer has a default
value, as the value will depend on the data provided by the user.
Renamed functions
- The function
find_duplicates() was renamed to
get_duplicate_forecasts().
- Renamed
interval_coverage_quantile() to
interval_coverage().
- “range” was consistently renamed to “interval_range” in the code.
The “range”-format (which was mostly used internally) was renamed to
“interval”-format
- Renamed
correlation() to
get_correlations() and plot_correlation() to
plot_correlations()
Deleted functions
- Removed abs_error and squared_error from the package in favour of
Metrics::ae and
Metrics::se.get_duplicate_forecasts() now
sorts outputs according to the forecast unit, making it easier to spot
duplicates. In addition, there is a counts option that
allows the user to display the number of duplicates for each forecast
unit, rather than the raw duplicated rows.
- Deleted the function
plot_ranges(). If you want to
continue using the functionality, you can find the function code here
or in the Deprecated-visualisations Vignette.
- Removed the function
plot_predictions(), as well as its
helper function make_NA(), in favour of a dedicated
Vignette that shows different ways of visualising predictions. For
future reference, the function code can be found here
(Issue #659) or in the Deprecated-visualisations Vignette.
- Removed the function
plot_score_table(). You can find
the code in the Deprecated-visualisations Vignette.
- Removed the function
merge_pred_and_obs() that was used
to merge two separate data frames with forecasts and observations. We
moved its contents to a new “Deprecated functions”-vignette.
- Removed
interval_coverage_sample() as users are now
expected to convert to a quantile format first before scoring.
- Function
set_forecast_unit() was deleted. Instead there
is now a forecast_unit argument in
as_forecast_<type>() as well as in
get_duplicate_forecasts().
- Removed
interval_coverage_dev_quantile(). Users can
still access the difference between nominal and actual interval coverage
using get_coverage().
pit(), pit_sample() and
plot_pit() have been removed and replaced by functionality
to create PIT histograms (pit_histogram_sampel() and
get_pit_histogram())
Function changes
bias_quantile() changed the way it handles forecasts
where the median is missing: The median is now imputed by linear
interpolation between the innermost quantiles. Previously, we imputed
the median by simply taking the mean of the innermost quantiles.- In contrast to the previous
correlation function,
get_correlations doesn’t round correlations by default.
Instead, plot_correlations now has a digits
argument that allows users to round correlations before plotting them.
Alternatively, using dplyr, you could call something like
mutate(correlations, across(where(is.numeric), \(x) signif(x, digits = 2)))
on the output of get_correlations.
wis() now errors by default if not all quantile levels
form valid prediction intervals and returns NA if there are
missing values. Previously, na.rm was set to
TRUE by default, which could lead to unexpected results, if
users are not aware of this.
Internal package updates
- The deprecated
..density.. was replaced with
after_stat(density) in ggplot calls.
- Files ending in “.Rda” were renamed to “.rds” where appropriate when
used together with
saveRDS() or
readRDS().
- Added a subsetting
[ operator for scores, so that the
score name attribute gets preserved when subsetting.
- Switched to using
cli for condition handling and
signalling, and added tests for all the check_*() and
test_*() functions. See #583 by @jamesmbaazam and reviewed by @nikosbosse and @seabbs.
scoringutils now requires R >= 4.0
Documentation and testing
- Updates documentation for most functions and made sure all functions
have documented return statements
- Documentation pkgdown pages are now created both for the stable and
dev versions.
- Added unit tests for many functions
scoringutils 1.2.2
Package updates
scoringutils now depends on R 3.6. The change was made
since packages testthat and lifecycle, which
are used in scoringutils now require R 3.6. We also updated
the Github action CI check to work with R 3.6 now.- Added a new PR template with a checklist of things to be included in
PRs to facilitate the development and review process
Bug fixes
- Fixes a bug with
set_forecast_unit() where the function
only worked with a data.table, but not a data.frame as an input.
- The metrics table in the vignette Details
on the metrics implemented in
scoringutils had
duplicated entries. This was fixed by removing the duplicated rows.
scoringutils 1.2.1
Package updates
- This minor update fixes a few issues related to gh actions and the
vignettes displayed at epiforecasts.io/scoringutils. It
- Gets rid of the preferably package in _pkgdown.yml. The theme had a
toggle between light and dark theme that didn’t work properly
- Updates the gh pages deploy action to v4 and also cleans up files
when triggered
- Introduces a gh action to automatically render the Readme from
Readme.Rmd
- Removes links to vignettes that have been renamed
scoringutils 1.2.0
This major release contains a range of new features and bug fixes
that have been introduced in minor releases since 1.1.0.
The most important changes are:
- Documentation updated to reflect changes since version 1.1.0,
including new transform and workflow functions.
- New
set_forecast_unit() function allows manual setting
of forecast unit.
summarise_scores() gains new across
argument for summarizing across variables.- New
transform_forecasts() and log_shift()
functions allow forecast transformations. See the documentation for
transform_forecasts() for more details and an example use
case.
- Input checks and test coverage improved for bias functions.
- Bug fix in
get_prediction_type() for integer matrix
input.
- Links to scoringutils paper and citation updates.
- Warning added in
interval_score() for small interval
ranges.
- Linting updates and improvements.
Thanks to @nikosbosse, @seabbs, and @sbfnk for code and review contributions.
Thanks to @bisaloo
for the suggestion to use a linting GitHub Action that only triggers on
changes, and @adrian-lison for the suggestion to add
a warning to interval_score() if the interval range is
between 0 and 1.
Package updates
- The documentation was updated to reflect the recent changes since
scoringutils 1.1.0. In particular, usage of the functions
set_forecast_unit(), check_forecasts() and
transform_forecasts() are now documented in the Vignettes.
The introduction of these functions enhances the overall workflow and
help to make the code more readable. All functions are designed to be
used together with the pipe operator. For example, one can now use
something like the following:
example_quantile |>
set_forecast_unit(c("model", "location", "forecast_date", "horizon", "target_type")) |>
check_forecasts() |>
score()
Documentation for the transform_forecasts() has also
been extended. This functions allows the user to easily add
transformations of forecasts, as suggested in the paper “Scoring
epidemiological forecasts on transformed scales”. In an
epidemiological context, for example, it may make sense to apply the
natural logarithm first before scoring forecasts, in order to obtain
scores that reflect how well models are able to predict exponential
growth rates, rather than absolute values. Users can now do something
like the following to score a transformed version of the data in
addition to the original one:
data <- example_quantile[true_value > 0, ]
data |>
transform_forecasts(fun = log_shift, offset = 1) |>
score() |>
summarise_scores(by = c("model", "scale"))
Here we use the log_shift() function to apply a
logarithmic transformation to the forecasts. This function was
introduced in scoringutils 1.1.2 as a helper function that
acts just like log(), but has an additional argument
offset that can add a number to every prediction and
observed value before applying the log transformation.
Feature updates
- Made
check_forecasts() and score()
pipeable (see issue #290). This means that users can now directly use
the output of check_forecasts() as input for
score(). As score() otherwise runs
check_forecasts() internally anyway this simply makes the
step explicit and helps writing clearer code.
scoringutils 1.1.7
Release by @seabbs
in #305. Reviewed by @nikosbosse and @sbfnk.
Breaking changes
- The
prediction_type argument of
get_forecast_unit() has been changed dropped. Instead a new
internal function prediction_is_quantile() is used to
detect if a quantile variable is present. Whilst this is an internal
function it may impact some users as it is accessible via
`find_duplicates().
Package updates
- Made imputation of the median in
bias_range() and
bias_quantile() more obvious to the user as this may cause
unexpected behaviour.
- Simplified
bias_range() so that it uses
bias_quantile() internally.
- Added additional input checks to
bias_range(),
bias_quantile(), and check_predictions() to
make sure that the input is valid.
- Improve the coverage of unit tests for
bias_range(),
bias_quantile(), and bias_sample().
- Updated pairwise comparison unit tests to use more realistic
data.
Bug fixes
- Fixed a bug in
get_prediction_type() which led to it
being unable to correctly detect integer (instead categorising them as
continuous) forecasts when the input was a matrix. This issue impacted
bias_sample() and also score() when used with
integer forecasts resulting in lower bias scores than expected.
scoringutils 1.1.6
Feature updates
- Added a new argument,
across, to
summarise_scores(). This argument allows the user to
summarise scores across different forecast units as an alternative to
specifying by. See the documentation for
summarise_scores() for more details and an example use
case.
scoringutils 1.1.5
Feature updates
- Added a new function,
set_forecast_unit() that allows
the user to set the forecast unit manually. The function removes all
columns that are not relevant for uniquely identifying a single
forecast. If not done manually, scoringutils attempts to
determine the unit of a single automatically by simply assuming that all
column names are relevant to determine the forecast unit. This can lead
to unexpected behaviour, so setting the forecast unit explicitly can
help make the code easier to debug and easier to read (see issue #268).
When used as part of a workflow, set_forecast_unit() can be
directly piped into check_forecasts() to check everything
is in order.
scoringutils 1.1.4
Package updates
scoringutils 1.1.3
Package updates
- Added a warning to
interval_score() if the interval
range is between 0 and 1. Thanks to @adrian-lison (see #277) for the
suggestion.
Package updates
- Switched to a linting GitHub Action that only triggers on changes.
Inspired by @bisaloo
recent contribution to the
epinowcast
package.
- Updated package linters to be more extensive. Inspired by @bisaloo recent
contribution to the
epinowcast
package.
- Resolved all flagged linting issues across the package.
scoringutils 1.1.2
Feature updates
- Added a new function,
transform_forecasts() to make it
easy to transform forecasts before scoring them, as suggested in Bosse
et al. (2023),
https://www.medrxiv.org/content/10.1101/2023.01.23.23284722v1.
- Added a function,
log_shift() that implements the
default transformation function. The function allows to add an offset
before applying the logarithm.
scoringutils 1.1.1
- Added a small change to
interval_score() which
explicitly converts the logical vector to a numeric one. This should
happen implicitly anyway, but is now done explicitly in order to avoid
issues that may come up if the input vector has a type that doesn’t
allow the implicit conversion.
scoringutils 1.1.0
A minor update to the package with some bug fixes and minor
changes.
Feature updates
Package updates
- Removed the on attach message which warned of breaking changes in
1.0.0.
- Renamed the
metric argument of
summarise_scores() to relative_skill_metric.
This argument is now deprecated and will be removed in a future version
of the package. Please use the new argument instead.
- Updated the documentation for
score() and related
functions to make the soft requirement for a model column
in the input data more explicit.
- Updated the documentation for
score(),
pairwise_comparison() and summarise_scores()
to make it clearer what the unit of a single forecast is that is
required for computations
- Simplified the function
plot_pairwise_comparison()
which now only supports plotting mean score ratios or p-values and
removed the hybrid option to print both at the same time.
Bug fixes
- Missing baseline forecasts in
pairwise_comparison() now
trigger an explicit and informative error message.
- The requirements table in the getting started vignette is now
correct.
- Added support for an optional
sample column when using
a quantile forecast format. Previously this resulted in an error.
scoringutils 1.0.0
Major update to the package and most package functions with lots of
breaking changes.
Feature updates
- New and updated Readme and vignette.
- The proposed scoring workflow was reworked. Functions were changed
so they can easily be piped and have simplified arguments and
outputs.
New functions and function
changes
- The function
eval_forecasts() was replaced by a
function score() with a much reduced set of function
arguments.
- Functionality to summarise scores and to add relative skill scores
was moved to a function
summarise_scores()
- New function
check_forecasts() to analyse input data
before scoring
- New function
correlation() to compute correlations
between different metrics
- New function
add_coverage() to add coverage for
specific central prediction intervals.
- New function
avail_forecasts() allows to visualise the
number of available forecasts.
- New function
find_duplicates() to find duplicate
forecasts which cause an error.
- All plotting functions were renamed to begin with
plot_. Arguments were simplified.
- The function
pit() now works based on data.frames. The
old pit function was renamed to pit_sample().
PIT p-values were removed entirely.
- The function
plot_pit() now works directly with input
as produced by pit()
- Many data-handling functions were removed and input types for
score() were restricted to sample-based, quantile-based or
binary forecasts.
- The function
brier_score() now returns all brier
scores, rather than taking the mean before returning an output.
crps(), dss() and logs() were
renamed to crps_sample(), dss_sample(), and
logs_sample()
Bug fixes
- Testing was expanded
- Minor bugs were fixed, for example a bug in the
as_forecast_quantile() function
(https://github.com/epiforecasts/scoringutils/pull/223)
Package data updated
- Package data is now based on forecasts submitted to the European
Forecast Hub (https://covid19forecasthub.eu/).
- All example data files were renamed to begin with
example_.
- A new data set,
summary_metrics was included that
contains a summary of the metrics implemented in
scoringutils.
Other breaking changes
- The ‘sharpness’ component of the weighted interval score was renamed
to dispersion. This was done to make it more clear what the component
represents and to maintain consistency with what is used in other
places.
scoringutils 0.1.8
Feature updates
- Added a function
check_forecasts() that runs some basic
checks on the input data and provides feedback.
scoringutils 0.1.7.2
Package updates
- Minor bug fixes (previously, ‘interval_score’ needed to be among the
selected metrics).
- All data.tables are now returned as
table[] rather than
as table, such that they don’t have to be called twice to
display the contents.
scoringutils 0.1.7
Feature updates
- Added a function,
pairwise_comparison() that runs
pairwise comparisons between models on the output of
eval_forecasts()
- Added functionality to compute relative skill within
eval_forecasts().
- Added a function to visualise pairwise comparisons.
Package updates
- The WIS definition change introduced in version 0.1.5 was partly
corrected such that the difference in weighting is only introduced when
summarising over scores from different interval ranges.
- “sharpness” was renamed to ‘mad’ in the output of [score()] for
sample-based forecasts.
scoringutils 0.1.
Feature updates
eval_forecasts() can now handle a separate forecast and
truth data set as as input.eval_forecasts() now supports scoring point forecasts
along side quantiles in a quantile-based format. Currently the only
metric used is the absolute error.
Package updates
- Many functions, especially
eval_forecasts() got a major
rewrite. While functionality should be unchanged, the code should now be
easier to maintain
- Some of the data-handling functions got renamed, but old names are
supported as well for now.
scoringutils 0.1.5
Package updates
- Changed the default definition of the weighted interval score.
Previously, the median prediction was counted twice, but is no only
counted once. If you want to go back to the old behaviour, you can call
the interval_score function with the argument
count_median_twice = FALSE.
scoringutils 0.1.4
Feature updates
- Added basic plotting functionality to visualise scores. You can now
easily obtain diagnostic plots based on scores as produced by
score.
correlation_plot() shows correlation between
metrics.plot_ranges() shows contribution of different
prediction intervals to some chosen metric.plot_heatmap() visualises scores as heatmap.plot_score_table() shows a coloured summary table of
scores.
package updates
- Renamed “calibration” to “coverage”.
- Renamed “true_values” to “true_value” in data.frames.
- Renamed “predictions” to “prediction” in data.frames.
- Renamed “is_overprediction” to “overprediction”.
- Renamed “is_underprediction” to “underprediction”.
scoringutils 0.1.3
(Potentially) Breaking
changes
- The by argument in
score now has a slightly changed
meaning. It now denotes the lowest possible grouping unit, i.e. the unit
of one observation and needs to be specified explicitly. The default is
now NULL. The reason for this change is that most metrics
need scoring on the observation level and this the most consistent
implementation of this principle. The pit function receives its grouping
now from summarise_by. In a similar spirit,
summarise_by has to be specified explicitly and
e.g. doesn’t assume anymore that you want ‘range’ to be included.
- For the interval score,
weigh = TRUE is now the default
option.
- Renamed true_values to true_value and predictions to
prediction.
Feature updates
- Updated quantile evaluation metrics in
score. Bias as
well as calibration now take all quantiles into account.
- Included option to summarise scores according to a
summarise_by argument in score() The summary
can return the mean, the standard deviation as well as an arbitrary set
of quantiles.
score() can now return pit histograms.- Switched to
ggplot2 for plotting.
scoringutils 0.1.2
(Potentially) Breaking
changes
- All scores in score were consistently renamed to lower case.
Interval_score is now interval_score,
CRPS is now crps etc.
Feature updates
- Included support for grouping scores according to a vector of column
names in
score().
- Included support for passing down arguments to lower-level functions
in
score()
- Included support for three new metrics to score quantiles with
score(): bias, sharpness and calibration
Package updates
- Example data now has a horizon column to illustrate the use of
grouping.
- Documentation updated to explain the above listed changes.
scoringutils 0.1.1
Feature updates
- Included support for a long as well as wide input formats for
quantile forecasts that are scored with
score().
Package updates
- Updated documentation for the
score().
- Added badges to the
README.